Sistemas Inteligentes - Proyecto ML Aguacate
El aguacate es un fruto exotico que se obtiene del árbol tropical que posee el mismo nombre. En el mercado se encuentra de dos tipos: convencional y los orgánico.
Aunque varios estudios han demostrado que el aguacate orgánico posee una mayor cantidad de vitaminas y grasas buenas para los seres humanos, hay que tener en cuenta que su precio suele ser superior al convencional, entonces podemos encontrar que existen tanto pros como contras así cómo existen sus respectivos grupos de personas que prefieren solamente el uno o el otro.
Dado esto, se planteó diseñar y crear una herramienta de Machine Learning que permita determinar si el aguacate es de tipo orgánico o convencional en base a ciertas variables y características de este cómo el precio, el año, la región, el número total de aguacates vendidos y las ventas por variedad.
Los datos son tomados de unos de uno de los dataset que se encuentran en la plataforma Kaggle y sugeridos por el Profesor Fabio Gonzalez, el dataset con el que trabajaremos es el de Avocado prices, el cual fue descargado del sitio web Avocado prices en mayo de 2018.
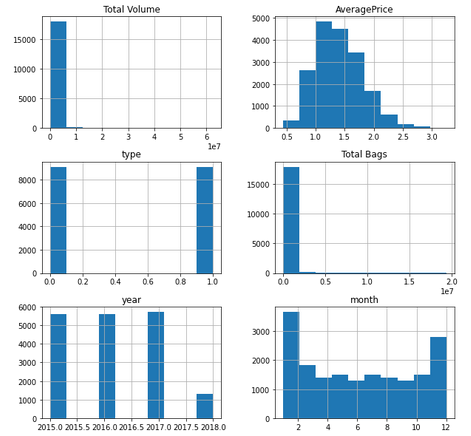
Inicialmente se realiza una previsualización de los datos de origen y se logra evidenciar que no tienen campos vacíos o caracteres especiales que necesiten algún tratamiento especial de limpieza. Se identifican variables que pueden dificultar el proceso para la construcción de modelo, por lo que es necesario su preprocesamiento, en primer lugar para la variable fecha se trata de la siguiente manera, se separa el dia, el mes en variables separadas dado que el año ya existía como variable en el dataset inicial, posteriormente se elimina la variable fecha, y la variable Unnamed: 0 que actuaba como índice incremental de dataset.
De igual manera se identifican variables categóricas: type y región, para las que se realiza la conversión a numéricas. Para la variable type se mapea el valor convencional a 0 y el valor orgánico a 1. Para la variable región se utiliza one-hot-encoding al ser aplicado el tamaño del dataset resultante es de 18249 filas × 67 columnas dado que nos convierte cada uno de los valores iniciales en nuevas columnas con valores de 0 o 1 en el caso que el registro pertenezca al estado o no.
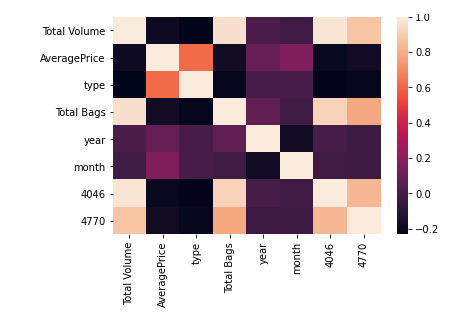
Para el observar la correlación entre las variables se observa que existe una correlación fuerte entre total volumen y el total de canastos como es de esperarse, y también para interés las variables del tipo de aguacate frente al precio promedio, esto lo observamos a través del siguiente mapa de calor
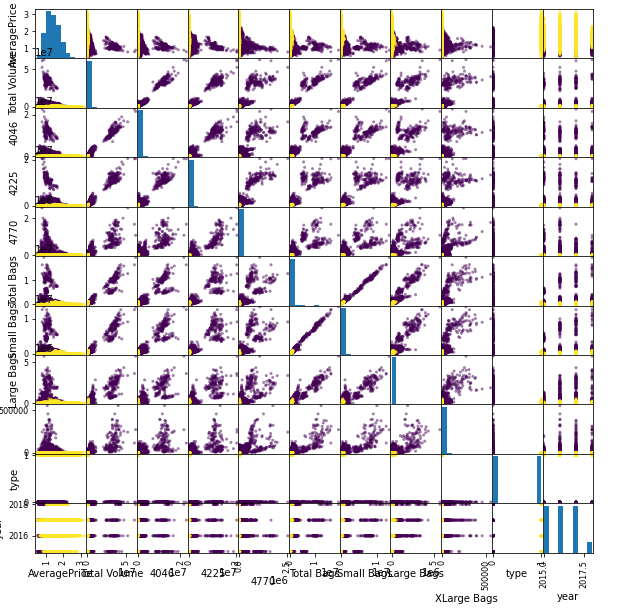
Excluimos las variables que no tienen interes y a través de una matriz de gráficos de dispersión que incluye gráficos de dispersión individuales para cualquier combinación de características se termina se realizar el proceso de visualización y selección de variables
MODELO: Random Forest
Para fines del proyecto se implementa el modelo de Random Forest, dado que la cantidad de datos se ajusta perfectamente a este tipo de modelo y de ser uno de los algoritmos por excelencia para resolver problemas de clasificación como es este el caso para predecir la clase 0 o 1, aguacate convencional u orgánico respectivamente, además de las ventajas que posee al no ser sensible a los hiperparametros y de no dar un sobreajuste al incrementar los estimadores.
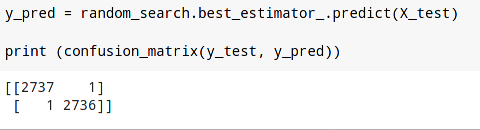
Particionamos los datos en 30% para pruebas y 70% de los datos para realizar el entrenamiento.
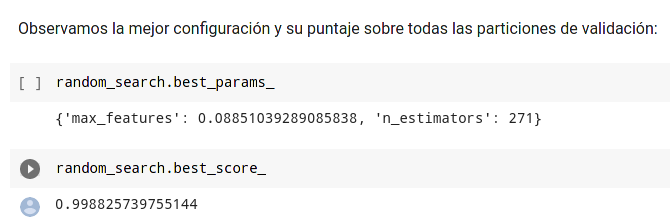
Se utilizan valores aleatorios con RandomizedSearchCV, evitando el uso de GridSearchCV dado que se ha demostrado que resulta ser más eficiente que optimizar los parámetros con GridSearchCV.
Para este caso se utilizan 5 pliegues evitando al máximo los sesgos que se pueden dar al escoger al azar datos de entrenamiento y la evaluación. para la optimización aleatoria con 20 iteraciones.
El tiempo que toma RandomizedSearchCV para entrenarse es de 25 minutos usando las 20 configuraciones. Observamos los datos con mejor desempeño a continuación luego del entrenamiento.